|
|
About Contribute Source |
| main/mps/ |
Matrix Product State / Tensor Train
The matrix product state (MPS)[1][2][3][4] or tensor train (TT)[5] tensor network is a factorization of a tensor with N indices into a chain-like product of three-index tensors. The MPS/TT is one of the best understood tensor networks for which many efficient algorithms have been developed. It is a special case of a tree tensor network.
A matrix product state / tensor train factorization of a tensor $T$ can be expressed in tensor diagram notation as
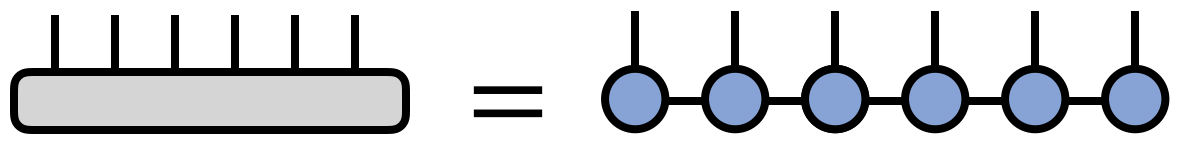
where for concreteness $T$ is taken to have six indices, but the pattern above can be generalized for a tensor with any number of indices.
Alternatively, the MPS/TT factorization of a tensor can be expressed in traditional notation as
\begin{equation} T^{s_1 s_2 s_3 s_4 s_5 s_6} = \sum_{\{\mathbf{\alpha}\}} A^{s_1}_{\alpha_1} A^{s_2}_{\alpha_1 \alpha_2} A^{s_3}_{\alpha_2 \alpha_3} A^{s_4}_{\alpha_3 \alpha_4} A^{s_5}_{\alpha_4 \alpha_5} A^{s_6}_{\alpha_5} \end{equation}
where the bond indices $\alpha$ are contracted, or summed over. Note that each of the $A$ tensors can in general be different from each other; instead of denoting them with different letters, it is a useful convention to just distinguish them by their indices.
Any tensor can be exactly represented in MPS / TT form for a large enough dimension of the bond indices $\alpha$. [4][5]
Bond Dimension / Rank
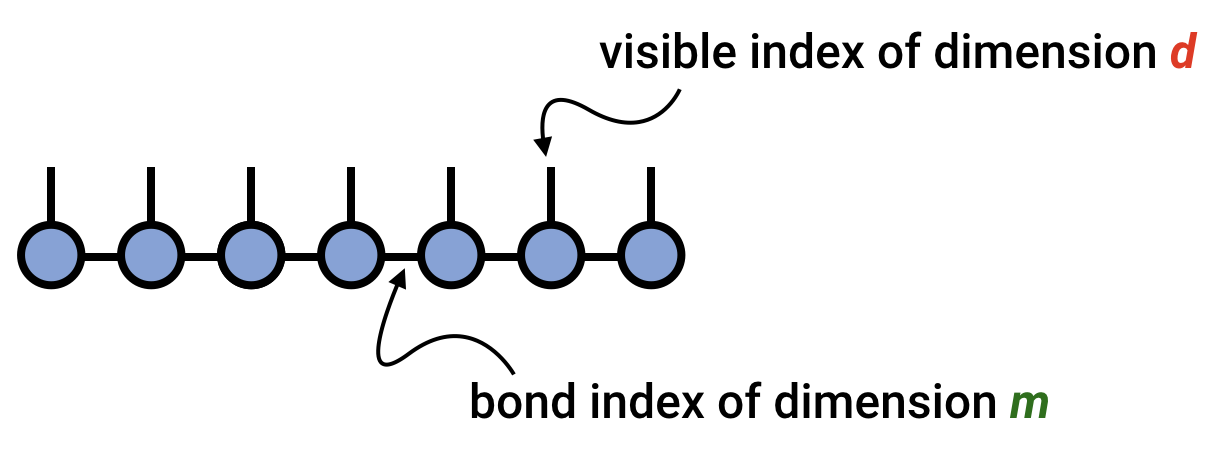
A key concept in understanding the matrix product state or tensor train factorization is the bond dimension or tensor-train rank, sometimes also called the virtual dimension. This is the dimension of the bond index connecting one tensor in the chain to the next, and can vary from bond to bond. The bond dimension can be thought of as a parameter controlling the expressivity of a MPS/TT network. In the example above, it is the dimension of the $\alpha$ indices.
Given a large enough bond dimension or rank, an MPS/TT can represent an arbitrary tensor. Consider a tensor $T^{s_1 s_2 \cdots s_N}$ having N indices all of dimension $d$. Then this tensor can always be represented exactly as an MPS/TT with bond dimension $m=d^{N/2}$.
However, in most applications the MPS/TT form is used as an approximation. In such cases, the bond dimension or rank is either fixed at a moderate size, or determined adaptively.
Number of Parameters
Consider a tensor with $N$ indices, each of dimension $d$. Generically, such a tensor must be specified by $d^N$ parameters. In contrast, representing such a tensor by an MPS/TT network of bond dimension $m$ requires
\begin{equation} N d m^2 \end{equation}
parameters, and this number can be reduced even further by imposing or exploiting certain constraints on the factor tensors.
If the MPS/TT representation of the tensor is a good approximation, then it represents a massive compression from a set of parameters growing exponentially with $N$, to a set of parameters growing just linearly with $N$.
It is possible to reduce the number of parameters even further, without loss of expressive power, by exploiting the redundancy inherent in the MPS/TT network. For more information about this redundancy, see the section on MPS/TT gauges below.
For a tensor with an infinite number of indices, the MPS/TT parameters can be made independent of $N$ by assuming that all of the factor tensors are the same (or the same up to a gauge transformation).
Elementary Operations Involving MPS/TT
The MPS/TT tensor network format makes it possible to efficiently carry out operations on a large, high-order tensor $T$ by manipulating the much smaller factors making up the MPS/TT representation of $T$.
There are many known algorithms for computations involving MPS/TT networks. Below, we highlight some of the simplest and most fundamental examples.
To read about other MPS/TT algorithms, see this page.
Retrieving a Component from an MPS/TT
Consider an order-$N$ tensor $T$. In general, cost of storing and retrieving its components scales exponentially with $N$. However, if $T$ can be represented or approximated by an MPS/TT network, one can obtain specific tensor components with an efficient algorithm.
Say we want to obtain the specific component $T^{s_1 s_2 s_3 \cdots s_N}$, where the values $s_1, s_2, s_3, \ldots, s_N$ should be considered fixed, yet arbitrary.
If $T$ is given by the MPS/TT \begin{equation} T^{s_1 s_2 s_3 \cdots s_N} = \sum_{\{\mathbf{\alpha}\}} A^{s_1}_{\alpha_1} A^{s_2}_{\alpha_1 \alpha_2} A^{s_3}_{\alpha_2 \alpha_3} \cdots A^{s_N}_{\alpha_{N-1}} \end{equation} then the algorithm to retrieve this component is very simple. Fix the $s_j$ indices on each of the $A$ factor tensors. Then, thinking of the tensor $A^{(s_1)}_{\alpha_1}$ as a row vector and $A^{(s_2)}_{\alpha_1 \alpha_2}$ as a matrix, contract these over the $\alpha_1$ index. The result is a new vector $L_{\alpha_2}$ that one can next contract with $A^{(s_3)}_{\alpha_2 \alpha_3}$. Continuing in this manner, one obtains the $s_1,s_2,s_3,\ldots,s_N$ component via a sequence of vector-matrix multiplications.
Diagramatically, the algorithm for retrieving a tensor component can be written as (for the illustrative case of $N=6$):
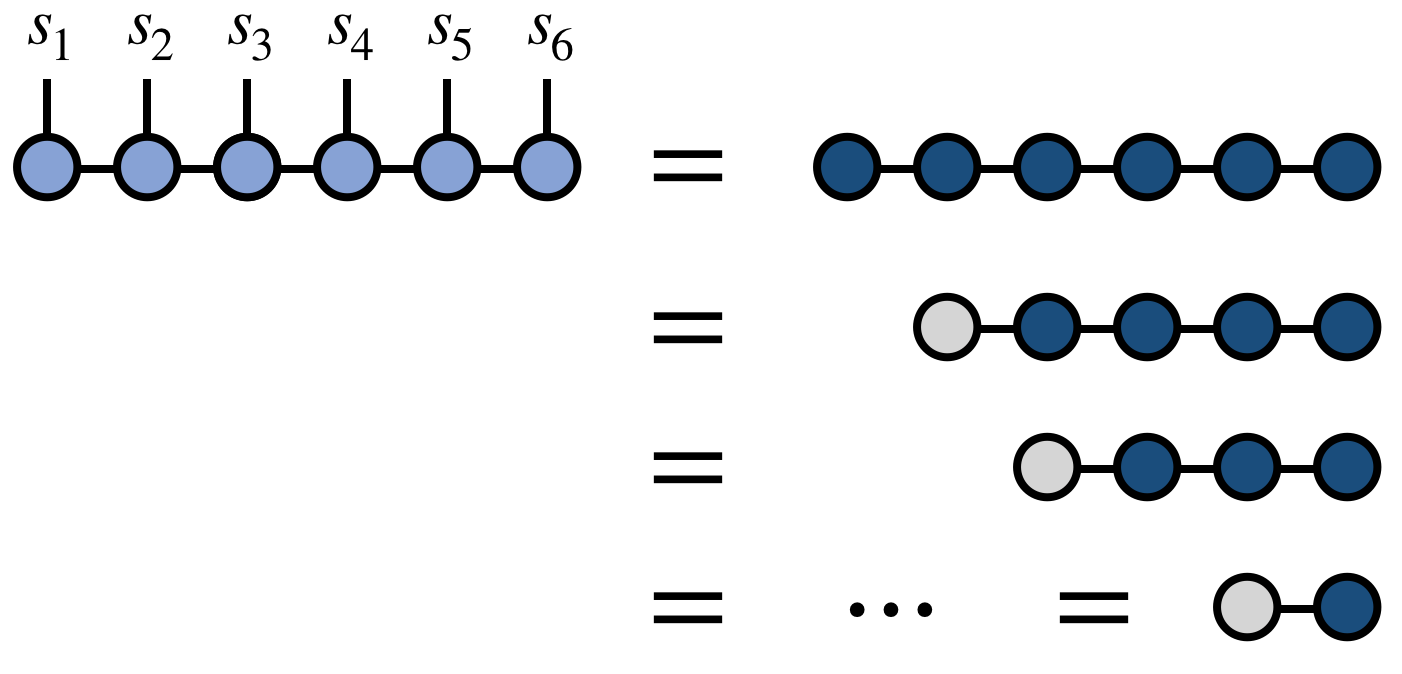
If the typical bond dimension of the MPS/TT is $m$, then the computational cost for retrieving a single tensor component scales as $N m^2$.
In the physics literature, the name matrix product state refers to the fact that an individual tensor component (in the context of a quantum state or wavefunction) is parameterized as a product of matrices as in the algorithm above. (This name is even clearer in the case of periodic MPS.)
Inner Product of Two MPS/TT [6]
Consider two high-order tensors $T^{s_1 s_2 s_3 s_4 s_5 s_6}$ and $W^{s_1 s_2 s_3 s_4 s_5 s_6}$. Say that we want to compute the inner product of $T$ and $W$, viewed as vectors. That is, we want to compute:
\begin{equation} \langle T, W\rangle = \sum_{\{\mathbf{s}\}} T^{s_1 s_2 s_3 s_4 s_5 s_6} W^{s_1 s_2 s_3 s_4 s_5 s_6} \end{equation}
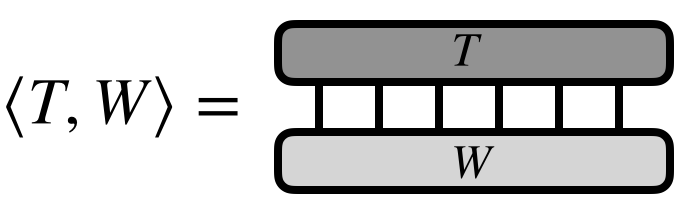
In the case of $T = W$, then this operation computes the Frobenius norm of $T$.
Now assume that $T$ and $W$ each can be efficiently represented or approximated by MPS/TT tensor networks as follows:
\begin{equation} T^{s_1 s_2 s_3 s_4 s_5 s_6} = \sum_{\{\mathbf{\alpha}\}} A^{s_1}_{\alpha_1} A^{s_2}_{\alpha_1 \alpha_2} A^{s_3}_{\alpha_2 \alpha_3} A^{s_4}_{\alpha_3 \alpha_4} A^{s_5}_{\alpha_4 \alpha_5} A^{s_6}_{\alpha_5} \end{equation}
\begin{equation} W^{s_1 s_2 s_3 s_4 s_5 s_6} = \sum_{\{\mathbf{\beta}\}} B^{s_1}_{\beta_1} B^{s_2}_{\beta_1 \beta_2} B^{s_3}_{\beta_2 \beta_3} B^{s_4}_{\beta_3 \beta_4} B^{s_5}_{\beta_4 \beta_5} B^{s_6}_{\beta_5} \end{equation}
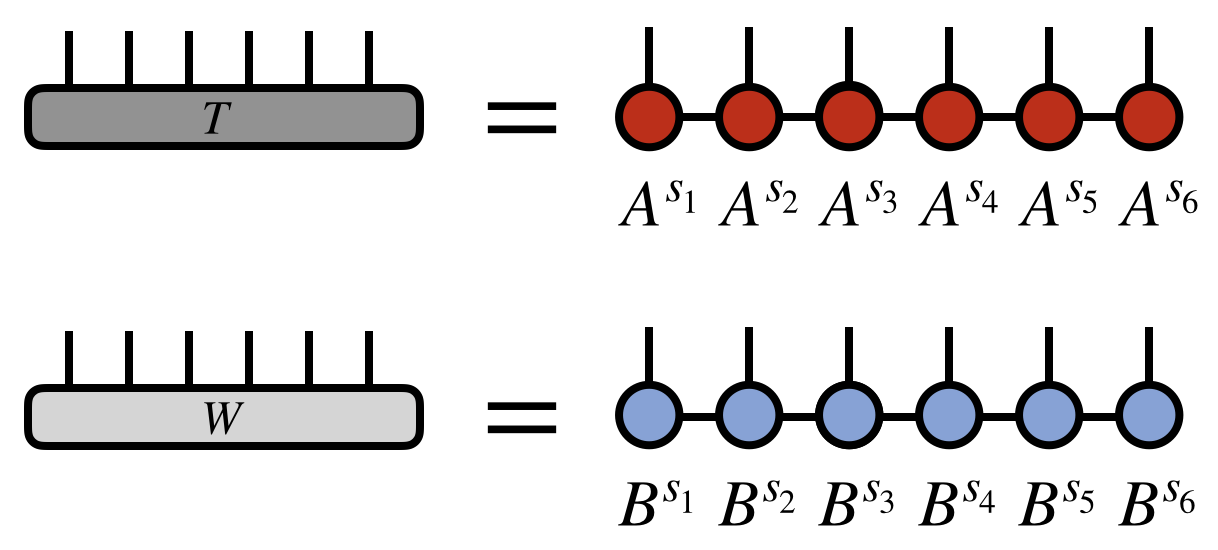
The strategy to efficiently compute $\langle T,W \rangle$ is to contract $A^{s_1}$ with $B^{s_1}$ over the $s_1$ index, forming a tensor $E^{\alpha_1}_{\beta_1}$. Then this tensor $E$ is contracted with $A^{s_2}$ and $B^{s_2}$ to form another intermediate tensor $E^{\alpha_2}_{\beta_2}$, etc.
Let us express this process more simply in diagrammatic notation:
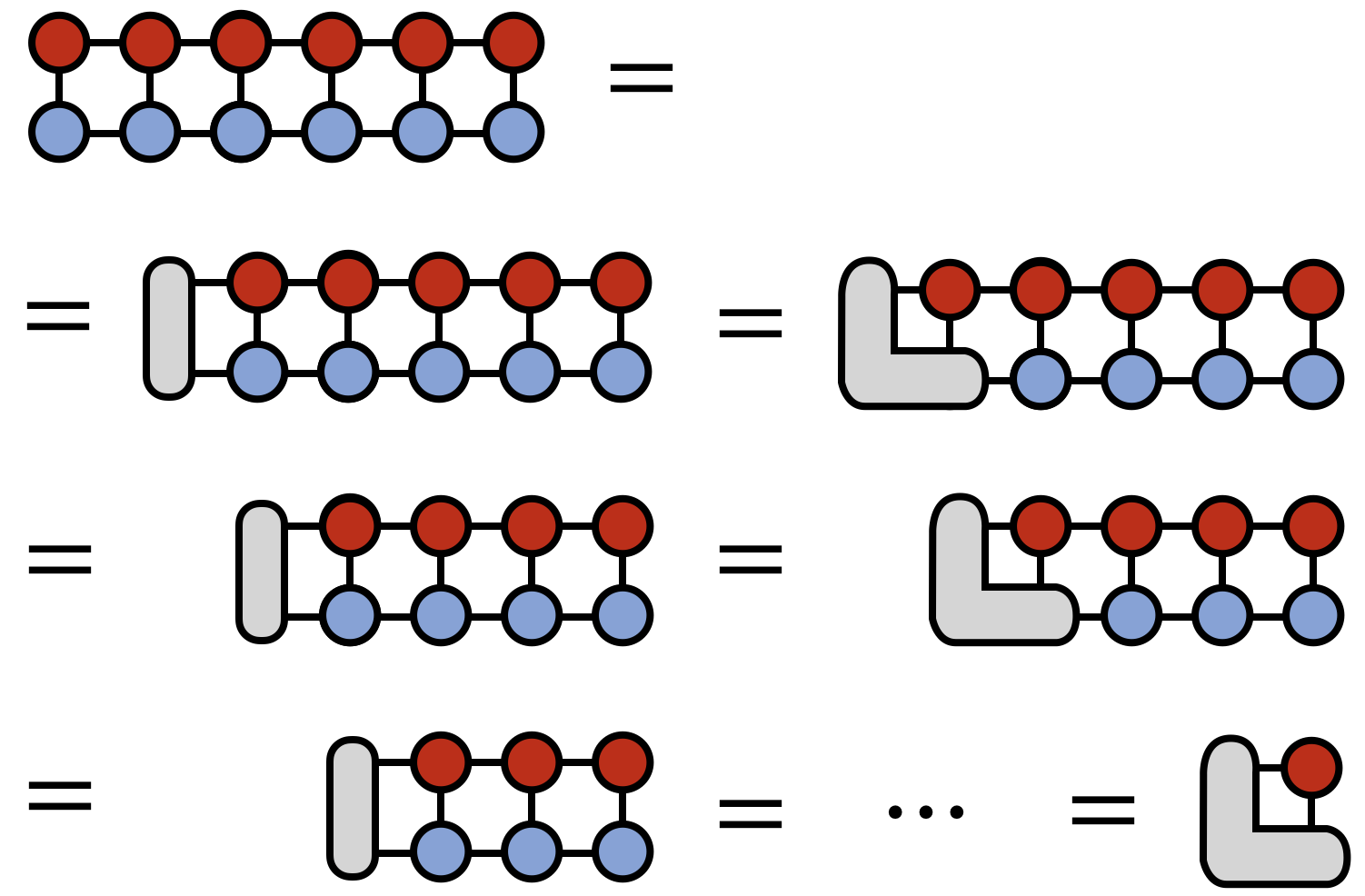
The above algorithm makes no approximations, yet is very efficient. A careful analysis of each step shows that the cost of the algorithm scales as
\begin{equation} N m^3\,d \end{equation}
where $m$ is the bond dimension or rank of the MPS/TT networks and $d$ is the dimension of the external indices. In contrast, if one worked with the full $T$ and $W$ tensors and did not use the MPS/TT form the cost of calculating $\langle T,W \rangle$ would be $d^N$.
Compression / Rounding [5][7]
A particularly powerful operation is the compression of a tensor network into MPS/TT form. Here we will focus on the compression of a larger bond dimension MPS/TT into one with a smaller dimension, but the algorithm can be readily generalized to other inputs, such as sums of MPS/TT networks, sums of rank-1 tensors, other tree tensor network formats, and more, with the result that these inputs are controllably approximated by a single MPS/TT.
The algorithm we follow here was proposed in Ref. 7. Other approaches to compression include SVD-based compression,[8] such as the TT-SVD algorithm,[5] or variational compression.[6]
For concreteness, say we want to compress an MPS/TT of bond dimension $M$ into one of bond dimension $m$, such that the new MPS/TT is as close as possible to the original one, in the sense of Euclidean distance (see above discussion of inner product).

The compression procedure begins with contracting two copies of the input MPS/TT network over all of the external indices, except the last external index.
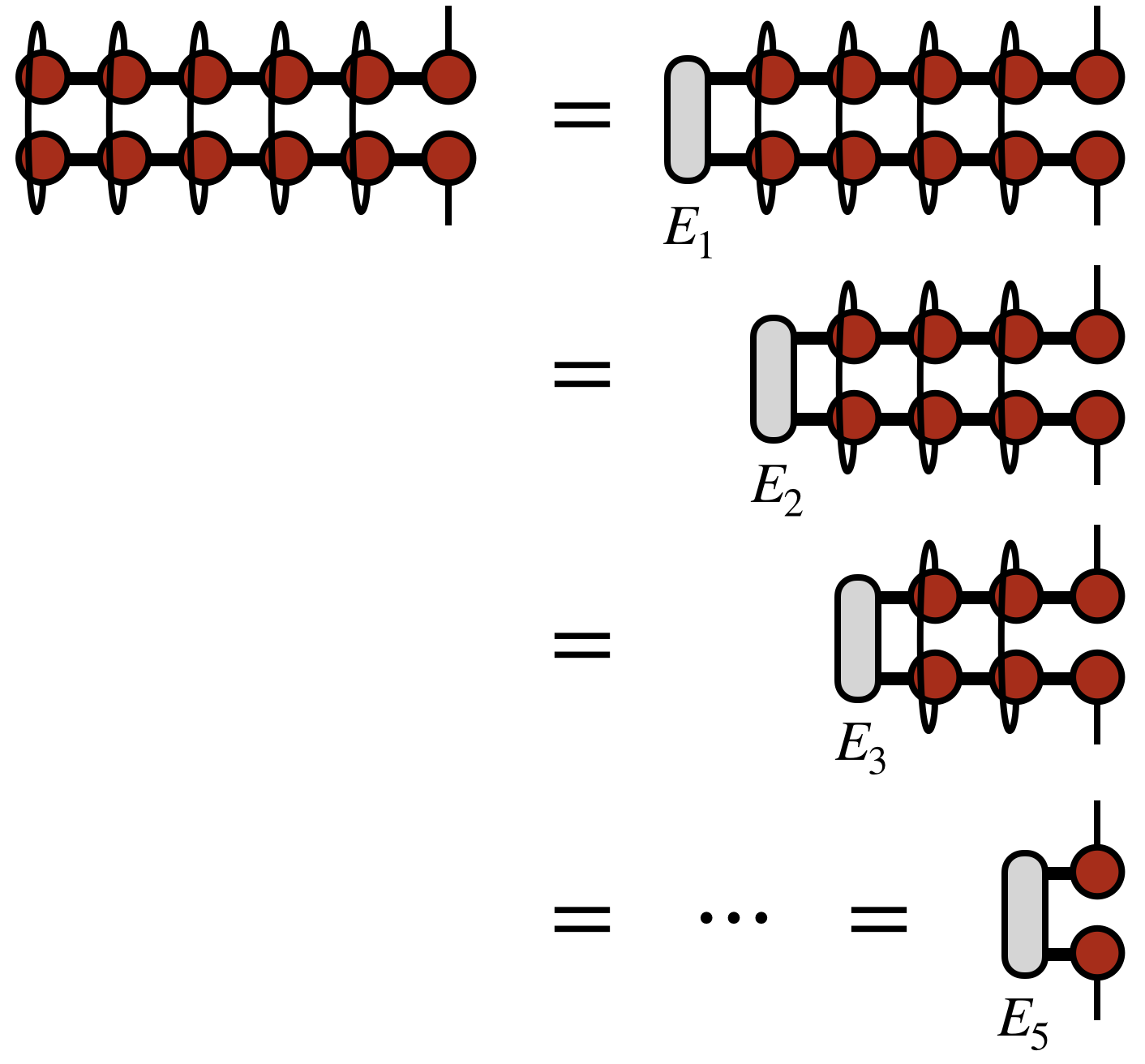
The intuition here is that the MPS/TT form is generated by a repeated SVD of a tensor. Just as an SVD of a matrix $M$ can be computed by diagonalizing $M^\dagger M$ and $M M^\dagger$, the MPS/TT appears twice in the diagrams above for the same reason.
To compute the contraction of the two MPS/TT copies efficiently, one forms the intermediate tensors labeled $E_1$, $E_2$, etc. as shown above. These tensors are saved for use in later steps of the algorithm, as will become clearer below.
Having computed all of the $E_j$ tensors, it is now possible to form the object $\rho_6$ below, which in physics is called a reduced density matrix, but more simply is the square of the tensor represented by the network, summed over all but its last index:
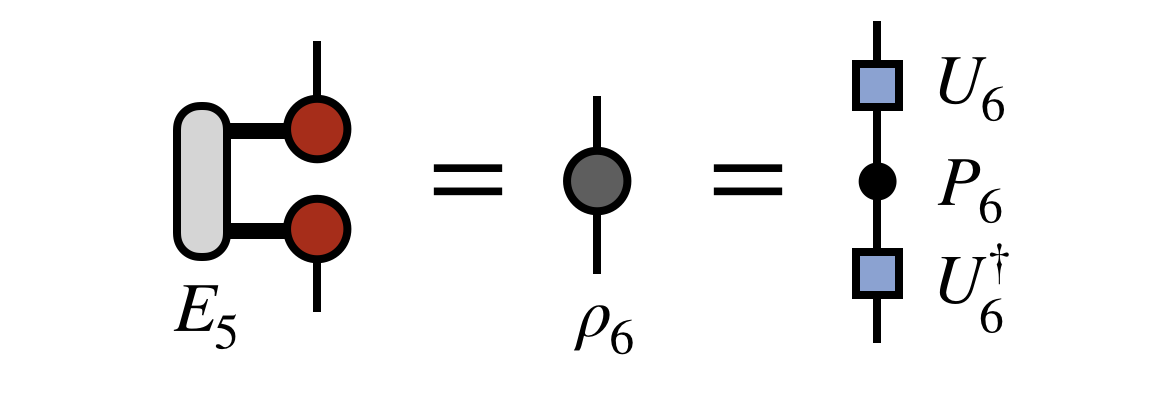
To begin forming the new, compressed MPS/TT, one diagonalizes $\rho_6$ as shown in the last expression above. It is a manifestly Hermitian matrix, so it can always be diagonalized by a unitary $U_6$, which is the box-shaped matrix in the last diagram above.
Crucially, at this step one only keeps the $m$ largest eigenvalues of $\rho_6$, discarding the rest and truncating the corresponding columns of $U_6$. The reason for this trunction is that the unitary $U_6$ is actually the first piece of the new, compressed MPS/TT we are constructing, which we wanted to have bond dimension $m$. In passing, we note that other truncation strategies are possible, such as truncating based on a threshold for small versus large eigenvalues, or even stochastically truncating by sampling over the eigenvalues.[9]
To obtain the next tensor of the new, compressed MPS/TT, one next forms the following “density matrix” and diagonalizes it (with truncation) as shown below
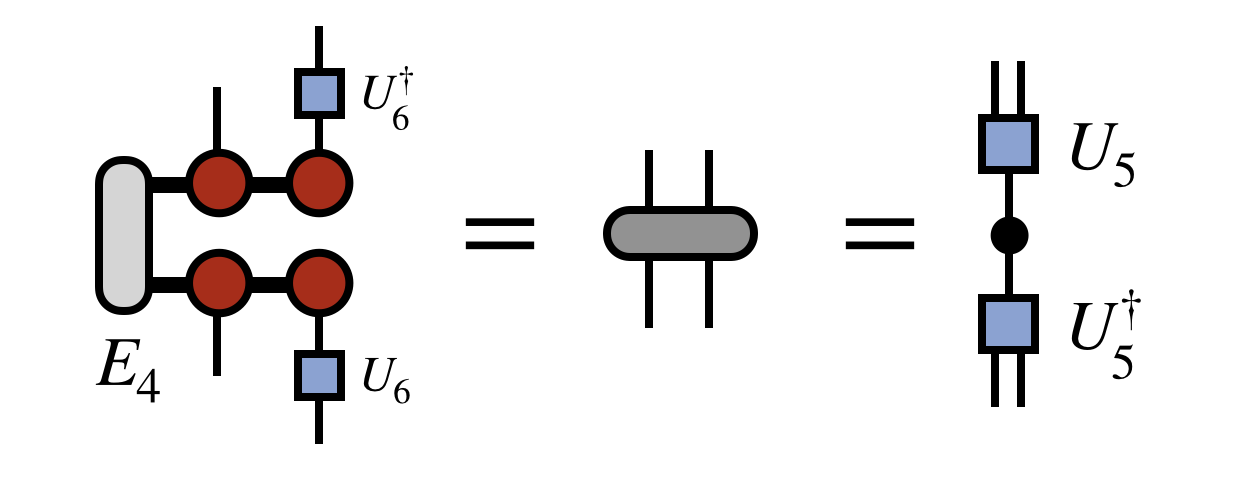
In defining this matrix, $U_6$ was used to transform the basis of the last site. As each $U$ is obtained, it is used in a similar way to compress the space, otherwise the cost of the algorithm would become unmanageable and each next $U$ tensor would not be defined in a basis compatible with the previous $U$’s.
Having obtained $U_5$ as shown above, one next computes the following density matrix, again using all previous $U$ tensors to rotate and compress the space spanned by all previous external indices as shown:
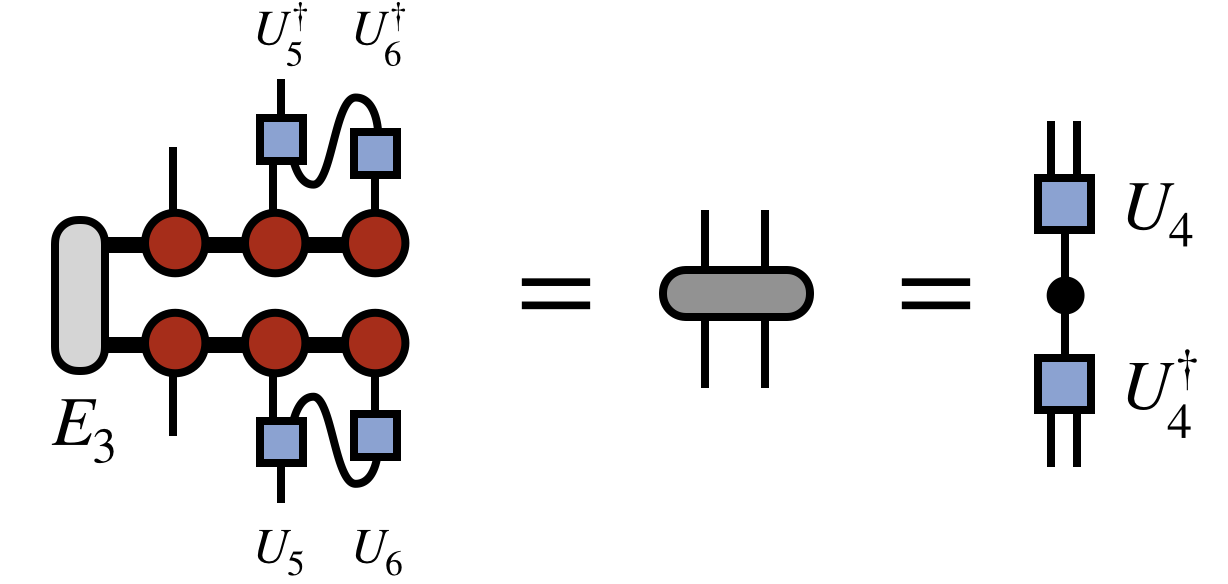
The pattern is repeated going further leftward down the chain to obtain $U_4$:
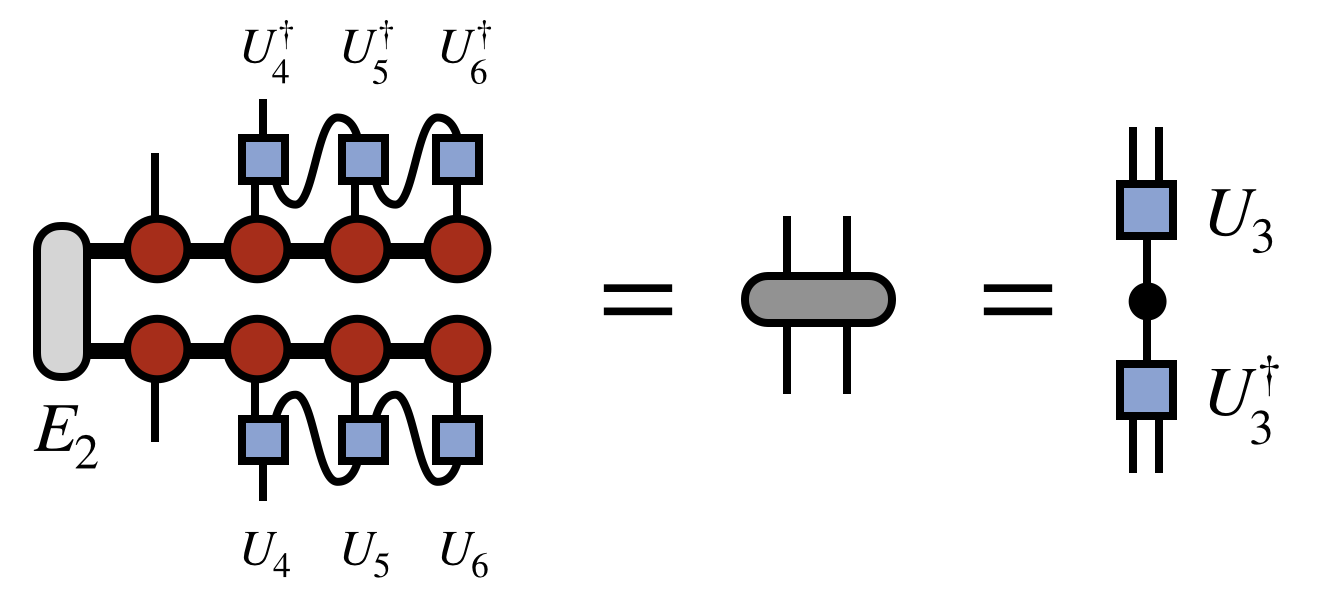
(In passing, note that a matter of efficiency, the contraction of the $U$ and $U^\dagger$ tensors with the uncompressed MPS/TT tensors does not have to be recalculated at each step, but partial contractions can be saved to form the next one efficiently. This sub-step of the algorithm is in fact identical to the inner product algorithm described above, except that it proceeds from right to left.)
Once all of the $U$ tensors are obtained by repeating the steps above, the last step of the algorithm is to obtain the first tensor of the new MPS/TT by the following contracted diagram:
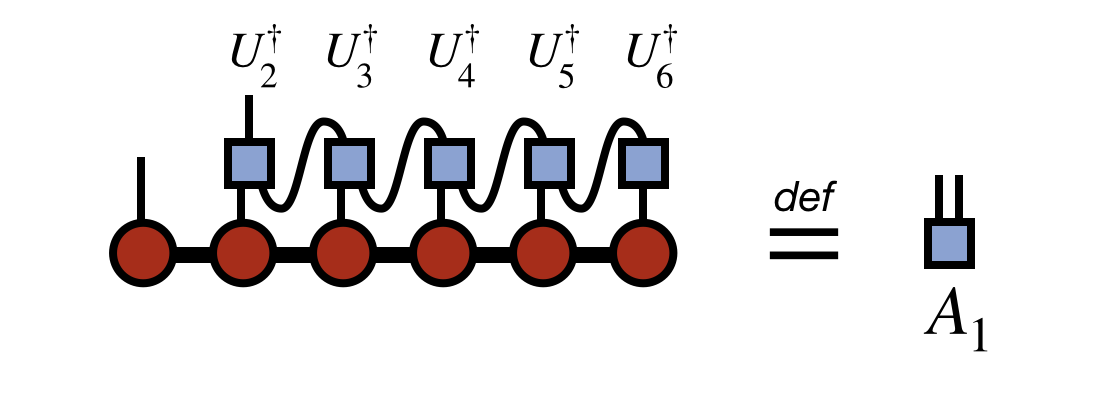
Assembling all of the pieces—the first tensor $A_1$ together with the $U_j$ tensors computed above—the final compressed version of the original MPS/TT is:
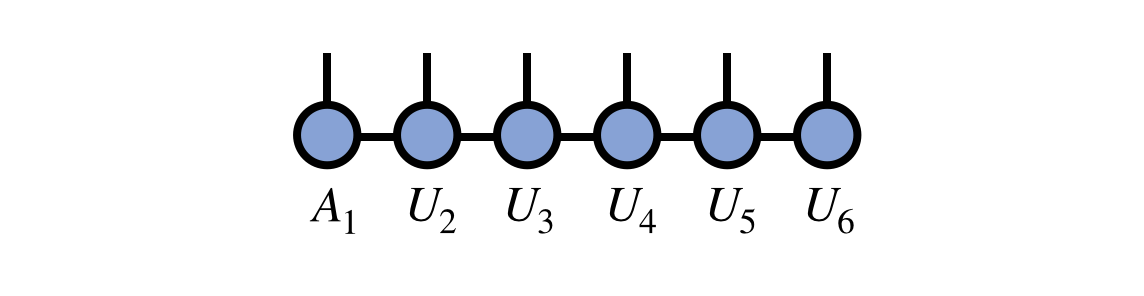
Note that in this last expression, the indices of various tensors have been oriented differently on the page than in their original definitions above. But recall that it is the connectivity of indices, not their orientation, that carries the meaning of tensor diagrams.
Gauges and Canonical Forms
The compression, or rounding, algorithm above leads to an interesting observation: the MPS/TT network after the compression can be made arbitrary close to the original one, but is made of isometric tensors $U_j$ (technically partial isometries). Because these tensors were the result of diagonalizing Hermitian matrices, they have the property that $U^\dagger U = I$, or diagrammatically:
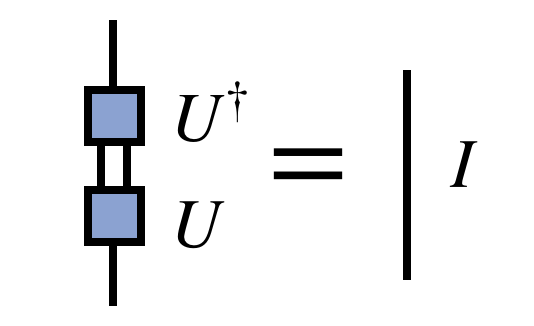
Written in the orientation these tensors take when viewed as part of an MPS/TT, they have the property that:
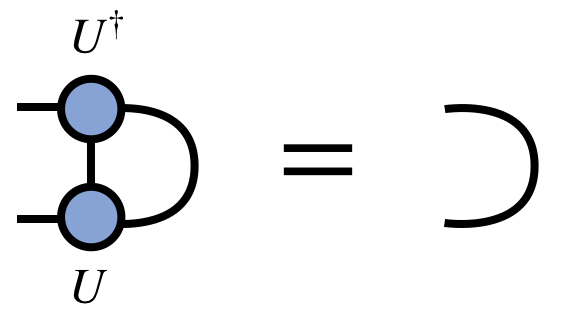
Connections to Other Formats and Concepts
-
An MPS/TT network can be viewed as a maximally unbalanced case of a tree tensor network.
-
MPS/TT with all factor tensors chosen to be the same and with a specified choice of boundary conditions are equivalent to weighted finite automata (WFA).[10] (However, the interpretation and applications of MPS and WFA can be rather different. For an interesting connection between the WFA and quantum physics literature see Ref. 11.)
-
MPS/TT networks constrained to have strictly non-negative entries can be mapped to hidden Markov models (HMM). Such constrained MPS have been studied using physics concepts in Ref. 12.
Further Reading and Resources
-
The Density-Matrix Renormalization Group in the Age of Matrix Product States[8] A very thorough review article focused on matrix product state tensor networks in a physics context, with many helpful figures.
-
Tensor Train Decomposition[5] A clear exposition of the MPS/TT network and algorithms geared at an applied mathematics audience.
-
A practical introduction to tensor networks: Matrix product states and projected entangled pair states[13] A friendly overview of tensor networks using physics terminology but aiming to be non-technical.
-
Hand-waving and Interpretive Dance: An Introductory Course on Tensor Networks[14] Detailed review article about tensor networks with a quantum information perspective.
References
- Finitely correlated states on quantum spin chains, M. Fannes, B. Nachtergaele, R. F. Werner, Communications in Mathematical Physics 144, 443–490 (1992)
- Groundstate properties of a generalized VBS-model, A. Klumper, A. Schadschneider, J. Zittartz, Zeitschrift fur Physik B Condensed Matter 87, 281–287 (1992)
- Thermodynamic Limit of Density Matrix Renormalization, Stellan Ostlund, Stefan Rommer, Phys. Rev. Lett. 75, 3537–3540 (1995), cond‑mat/9503107
- Efficient Classical Simulation of Slightly Entangled Quantum Computations, Guifre Vidal, Phys. Rev. Lett. 91, 147902 (2003), quant‑ph/0301063
- Tensor-Train Decomposition, I. Oseledets, SIAM Journal on Scientific Computing 33, 2295-2317 (2011)
- Matrix Product State Representations, D. Perez-Garcia, F. Verstraete, M. M. Wolf, J. I. Cirac, Quantum Info. Comput. 7, 401–430 (2007), quant‑ph/0608197
- From density-matrix renormalization group to matrix product states, Ian P. McCulloch, J. Stat. Mech., P10014 (2007), cond‑mat/0701428
- The density-matrix renormalization group in the age of matrix product states, U. Schollwock, Annals of Physics 326, 96–192 (2011), arxiv:1008.3477
- Unbiased Monte Carlo for the age of tensor networks, Andrew J. Ferris (2015), arxiv:1507.00767
- Spectral learning of weighted automata, Borja Balle, Xavier Carreras, Franco M Luque, Ariadna Quattoni, Machine learning 96, 33 (2014)
- Quadratic weighted automata: Spectral algorithm and likelihood maximization, Raphael Bailly, Journal of Machine Learning Research 20, 147–162 (2011)
- Stochastic Matrix Product States, Kristan Temme, Frank Verstraete, Phys. Rev. Lett. 104, 210502 (2010), arxiv:1003.2545
- A practical introduction to tensor networks: Matrix product states and projected entangled pair states, Roman Orus, Annals of Physics 349, 117 - 158 (2014)
- Hand-waving and interpretive dance: an introductory course on tensor networks, Jacob C Bridgeman, Christopher T Chubb, Journal of Physics A: Mathematical and Theoretical 50, 223001 (2017), arxiv:1603.03039
Edit This Page